Hallo,
das RAID1 mit btrfs auf einer DS218+ mit DSM 7.0.1 hat sich nach
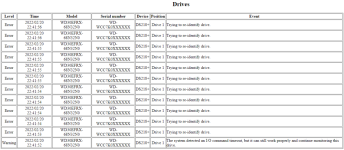
- EINER Warnung "The system detected an I/O command timeout, but it can still work properly and continue monitoring this drive."
- gefolgt von 11 "Trying to re-identify drive." Fehlern innerhalb der folgenden 3 Sekunden
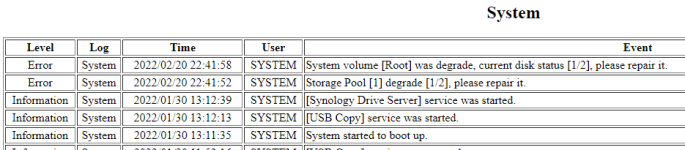
.. aufgelöst (Storage Pool [1] degrade [1/2], please repair it.) Disk ist eine WDC RED WD30EFRX-68N32N0 mit Firmware 82.00A82
Der Fehler scheint nur in einem kurzen Zeitfenster aufgetreten zu sein. Nichts offensichtliches kaputt. Dennoch lässt Synology kein Repair zu.
Frage: Verträgt sich da DSM701 nicht mit einer "alten" WD Red? Oder sehe ich nur den Festplattenfehler nicht? Mehr Details untenstehend.
Danke,
spachti
Test Result eines "S.M.A.R.T. Extended Test" kurz nach Auftreten noch im beagten NAS --> Healthy
Das waren die manuellen Tests bei Betriebsstunde 6519 und 6525. Die Fehler danach sind von diversen Reboots.
Aus dem Output von "smartctl -x" an einem Ubuntu-PC (Komplett im Anhang):
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 6565 -
# 2 Extended offline Completed without error 00% 6525 -
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 0
3 Spin_Up_Time POS--K 199 169 021 - 5008
4 Start_Stop_Count -O--CK 100 100 000 - 668
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 200 200 000 - 0
9 Power_On_Hours -O--CK 091 091 000 - 6571
10 Spin_Retry_Count -O--CK 100 100 000 - 0
11 Calibration_Retry_Count -O--CK 100 100 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 646
192 Power-Off_Retract_Count -O--CK 200 200 000 - 19
193 Load_Cycle_Count -O--CK 200 200 000 - 648
194 Temperature_Celsius -O---K 116 103 000 - 34
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 200 200 000 - 0
Device Statistics (GP Log 0x04)
Page Offset Size Value Flags Description
0x01 ===== = = === == General Statistics (rev 1) ==
0x01 0x008 4 646 --- Lifetime Power-On Resets
0x01 0x010 4 6571 --- Power-on Hours
0x01 0x018 6 3687888961 --- Logical Sectors Written
0x01 0x020 6 23938833 --- Number of Write Commands
0x01 0x028 6 294915136 --- Logical Sectors Read
0x01 0x030 6 2211790 --- Number of Read Commands
0x01 0x038 6 2180763520 --- Date and Time TimeStamp
0x03 ===== = = === == Rotating Media Statistics (rev 1) ==
0x03 0x008 4 6553 --- Spindle Motor Power-on Hours
0x03 0x010 4 6548 --- Head Flying Hours
0x03 0x018 4 668 --- Head Load Events
0x03 0x020 4 0 --- Number of Reallocated Logical Sectors
0x03 0x028 4 1517 --- Read Recovery Attempts
0x03 0x030 4 0 --- Number of Mechanical Start Failures
0x03 0x038 4 0 --- Number of Realloc. Candidate Logical Sectors
0x03 0x040 4 19 --- Number of High Priority Unload Events
0x04 ===== = = === == General Errors Statistics (rev 1) ==
0x04 0x008 4 18 --- Number of Reported Uncorrectable Errors
0x04 0x010 4 0 --- Resets Between Cmd Acceptance and Completion
0x05 ===== = = === == Temperature Statistics (rev 1) ==
0x05 0x008 1 34 --- Current Temperature
0x05 0x010 1 41 --- Average Short Term Temperature
0x05 0x018 1 42 --- Average Long Term Temperature
0x05 0x020 1 46 --- Highest Temperature
0x05 0x028 1 27 --- Lowest Temperature
0x05 0x030 1 44 --- Highest Average Short Term Temperature
0x05 0x038 1 32 --- Lowest Average Short Term Temperature
0x05 0x040 1 42 --- Highest Average Long Term Temperature
0x05 0x048 1 34 --- Lowest Average Long Term Temperature
0x05 0x050 4 0 --- Time in Over-Temperature
0x05 0x058 1 65 --- Specified Maximum Operating Temperature
0x05 0x060 4 0 --- Time in Under-Temperature
0x05 0x068 1 0 --- Specified Minimum Operating Temperature
0x06 ===== = = === == Transport Statistics (rev 1) ==
0x06 0x008 4 662 --- Number of Hardware Resets
0x06 0x010 4 2 --- Number of ASR Events
0x06 0x018 4 0 --- Number of Interface CRC Errors
|||_ C monitored condition met
||__ D supports DSN
|___ N normalized value
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 6 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 14 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000d 2 0 Non-CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x8000 4 13814 Vendor specific
Zusatzfrage: Wie komme ich (unter Linux) an ältere Log Einträge bzw. die Vendor Specific Events?
das RAID1 mit btrfs auf einer DS218+ mit DSM 7.0.1 hat sich nach
- EINER Warnung "The system detected an I/O command timeout, but it can still work properly and continue monitoring this drive."
- gefolgt von 11 "Trying to re-identify drive." Fehlern innerhalb der folgenden 3 Sekunden
.. aufgelöst (Storage Pool [1] degrade [1/2], please repair it.) Disk ist eine WDC RED WD30EFRX-68N32N0 mit Firmware 82.00A82
Der Fehler scheint nur in einem kurzen Zeitfenster aufgetreten zu sein. Nichts offensichtliches kaputt. Dennoch lässt Synology kein Repair zu.
Frage: Verträgt sich da DSM701 nicht mit einer "alten" WD Red? Oder sehe ich nur den Festplattenfehler nicht? Mehr Details untenstehend.
Danke,
spachti
Test Result eines "S.M.A.R.T. Extended Test" kurz nach Auftreten noch im beagten NAS --> Healthy
Das waren die manuellen Tests bei Betriebsstunde 6519 und 6525. Die Fehler danach sind von diversen Reboots.
Aus dem Output von "smartctl -x" an einem Ubuntu-PC (Komplett im Anhang):
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 6565 -
# 2 Extended offline Completed without error 00% 6525 -
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 0
3 Spin_Up_Time POS--K 199 169 021 - 5008
4 Start_Stop_Count -O--CK 100 100 000 - 668
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 200 200 000 - 0
9 Power_On_Hours -O--CK 091 091 000 - 6571
10 Spin_Retry_Count -O--CK 100 100 000 - 0
11 Calibration_Retry_Count -O--CK 100 100 000 - 0
12 Power_Cycle_Count -O--CK 100 100 000 - 646
192 Power-Off_Retract_Count -O--CK 200 200 000 - 19
193 Load_Cycle_Count -O--CK 200 200 000 - 648
194 Temperature_Celsius -O---K 116 103 000 - 34
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O--CK 200 200 000 - 0
200 Multi_Zone_Error_Rate ---R-- 200 200 000 - 0
Device Statistics (GP Log 0x04)
Page Offset Size Value Flags Description
0x01 ===== = = === == General Statistics (rev 1) ==
0x01 0x008 4 646 --- Lifetime Power-On Resets
0x01 0x010 4 6571 --- Power-on Hours
0x01 0x018 6 3687888961 --- Logical Sectors Written
0x01 0x020 6 23938833 --- Number of Write Commands
0x01 0x028 6 294915136 --- Logical Sectors Read
0x01 0x030 6 2211790 --- Number of Read Commands
0x01 0x038 6 2180763520 --- Date and Time TimeStamp
0x03 ===== = = === == Rotating Media Statistics (rev 1) ==
0x03 0x008 4 6553 --- Spindle Motor Power-on Hours
0x03 0x010 4 6548 --- Head Flying Hours
0x03 0x018 4 668 --- Head Load Events
0x03 0x020 4 0 --- Number of Reallocated Logical Sectors
0x03 0x028 4 1517 --- Read Recovery Attempts
0x03 0x030 4 0 --- Number of Mechanical Start Failures
0x03 0x038 4 0 --- Number of Realloc. Candidate Logical Sectors
0x03 0x040 4 19 --- Number of High Priority Unload Events
0x04 ===== = = === == General Errors Statistics (rev 1) ==
0x04 0x008 4 18 --- Number of Reported Uncorrectable Errors
0x04 0x010 4 0 --- Resets Between Cmd Acceptance and Completion
0x05 ===== = = === == Temperature Statistics (rev 1) ==
0x05 0x008 1 34 --- Current Temperature
0x05 0x010 1 41 --- Average Short Term Temperature
0x05 0x018 1 42 --- Average Long Term Temperature
0x05 0x020 1 46 --- Highest Temperature
0x05 0x028 1 27 --- Lowest Temperature
0x05 0x030 1 44 --- Highest Average Short Term Temperature
0x05 0x038 1 32 --- Lowest Average Short Term Temperature
0x05 0x040 1 42 --- Highest Average Long Term Temperature
0x05 0x048 1 34 --- Lowest Average Long Term Temperature
0x05 0x050 4 0 --- Time in Over-Temperature
0x05 0x058 1 65 --- Specified Maximum Operating Temperature
0x05 0x060 4 0 --- Time in Under-Temperature
0x05 0x068 1 0 --- Specified Minimum Operating Temperature
0x06 ===== = = === == Transport Statistics (rev 1) ==
0x06 0x008 4 662 --- Number of Hardware Resets
0x06 0x010 4 2 --- Number of ASR Events
0x06 0x018 4 0 --- Number of Interface CRC Errors
|||_ C monitored condition met
||__ D supports DSN
|___ N normalized value
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 6 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 14 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000d 2 0 Non-CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x8000 4 13814 Vendor specific
Zusatzfrage: Wie komme ich (unter Linux) an ältere Log Einträge bzw. die Vendor Specific Events?
Anhänge
Zuletzt bearbeitet: