

- Mitglied seit
- 28. Mrz 2010
- Beiträge
- 383
- Punkte für Reaktionen
- 6
- Punkte
- 24
Hallo, ich nutze synOCR schon lange und gerne. Von einem HP Multifunktionsdrucker als PDF gescannt landen alle PDFs auf der DS und werden dort mit synOCR bearbeitet. Klappt prima soweit. Die Dateien werden dann meist mit der MacOS Vorschau weiterverarbeitet.
Allerdings ist mir immer mal wieder aufgefallen, dass manche PDFs die direkt nach synOCR noch einwandfrei waren, irgendwann nur noch Fragezeichen statt Buchstaben enthielten. Also wenn man dann den Text aus der PDF rauskopierte waren dort statt Buchstaben nur noch Fragezeichen. Auch die Textsuche in diesen PDF Dateien funktioniert dann nicht mehr.
Es hat eine Weile gedauert bis ich die Ursache fand. Die PDF ist anfangs nach synOCR noch in Ordnung. Wenn man aber diese PDF mit der Mac Vorschau öffnet, und zB. bei mehrseitigen Dokumenten eine Seite rauslöscht oder hinzufügt, die PDF anschliessend neu abspeichert, dann ist der Textlayer der PDF kaputt und enthält nur noch Fragezeichen. Das ist hier jedesmal reproduzierbar.
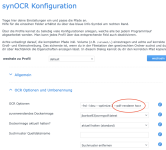
Nach etwas rumprobieren und Doku lesen, habe ich eine Lösung für mich gefunden damit das nicht mehr passiert. synOCR nutzt ja "unter der Haube" OCRmyPDF. In der Doku von OCRmyPDF wird erwähnt, dass in dem Paket zwei PDF Renderer enthalten sind ("sandwich" und "hocr"). Als Standard Renderer wird die neue Version "sandwich" verwendet. Und genau damit erzeugte PDF Dateien verursachen bei mir das oben erwähnte Problem. Nachdem ich auf die ältere Version des PDF Renderers ("hocr") umgestellt hatte war das Problem verschwunden (siehe angehängten Screenshot).
Vielleicht hilfts ja dem einen oder anderen Mac User.
Allerdings ist mir immer mal wieder aufgefallen, dass manche PDFs die direkt nach synOCR noch einwandfrei waren, irgendwann nur noch Fragezeichen statt Buchstaben enthielten. Also wenn man dann den Text aus der PDF rauskopierte waren dort statt Buchstaben nur noch Fragezeichen. Auch die Textsuche in diesen PDF Dateien funktioniert dann nicht mehr.
Es hat eine Weile gedauert bis ich die Ursache fand. Die PDF ist anfangs nach synOCR noch in Ordnung. Wenn man aber diese PDF mit der Mac Vorschau öffnet, und zB. bei mehrseitigen Dokumenten eine Seite rauslöscht oder hinzufügt, die PDF anschliessend neu abspeichert, dann ist der Textlayer der PDF kaputt und enthält nur noch Fragezeichen. Das ist hier jedesmal reproduzierbar.
Nach etwas rumprobieren und Doku lesen, habe ich eine Lösung für mich gefunden damit das nicht mehr passiert. synOCR nutzt ja "unter der Haube" OCRmyPDF. In der Doku von OCRmyPDF wird erwähnt, dass in dem Paket zwei PDF Renderer enthalten sind ("sandwich" und "hocr"). Als Standard Renderer wird die neue Version "sandwich" verwendet. Und genau damit erzeugte PDF Dateien verursachen bei mir das oben erwähnte Problem. Nachdem ich auf die ältere Version des PDF Renderers ("hocr") umgestellt hatte war das Problem verschwunden (siehe angehängten Screenshot).
Vielleicht hilfts ja dem einen oder anderen Mac User.
Anhänge
Zuletzt bearbeitet:






