Moin moin,
ich habe einen weiteren Kunden mit einem ähnlichen Problem -> Gleichzeitiger Ausfall beider SSDs vom Cache. Da kam mir in den Sinn, dass ich hier ja irgendwann mal einen Beitrag erstellt habe und wollte mich final noch mal zurückmelden.
Wir haben irgendwann nach meiner letzten Nachricht tatsächlich das NAS durchgestartet. Danach ging dann gar nichts mehr, der Speicherpool wurde nicht mal mehr "geladen", wir konnten auf keinerlei Daten mehr zugreifen. Wie das immer so ist in solchen Fällen, gab es zusätzlich dazu auch noch Probleme mit dem Backup und das auch noch an beiden Standorten. Wir hatten also Daten von vor 14 Tagen und konnten auf die aktuellen Daten nicht mehr zugreifen (der "7er" im Lotto, quasi unmöglich). Entsprechend viel Aufwand haben wir investiert, um noch irgendwas zu retten.
Wenn man versucht hat, den Speicherpool zu mounten, ist die ganze Kiste abgestürzt. Wir haben das diverse Male probiert, immer ohne Erfolg. Am Ende musste das NAS nach jedem Mount neu gestartet werden. Nachdem wir also stundenlang recherchiert und probiert haben, kristallisierte sich ein Problem mit dem BTRFS-Dateisystem heraus. Wir haben dann recherchiert und auch einiges an Input dazu gefunden:
https://www.reddit.com/r/btrfs/comments/jnu26l/corrupted_synology_btrfs_storage/
https://www.reddit.com/r/btrfs/comments/kntg3e/synologys_volume_recovery_failed/
https://www.linuxquestions.org/ques...%93couldn%27t-open-file-system%94-4175529628/
https://xpenology.com/forum/topic/24911-last-chance-repair-a-crashed-btrfs-volume/
https://manpages.ubuntu.com/manpages/bionic/man8/btrfs-rescue.8.html
https://kb.synology.com/en-my/DSM/tutorial/What_to_do_when_volume_is_read_only
Während sich eine Person nun also mit dem Thema Backups beschäftigt hat, hat eine andere Person sich per IRC (gibt es tatsächlich noch) mit den Spezialisten aus dem BTRFS-Bereich unterhalten. Im IRC war geballte Fachkompetenz vorhanden, von BTRFS-Entwicklern über eingefleischte Linux-Entwickler, da war von allem was dabei und alle waren sehr hilfsbereit. Wenn ich das noch richtig zusammenbekomme war das Problem, dass unser BTRFS-Device-Tree nicht mehr lesbar bzw. nicht mehr vorhanden war. Wir haben in Absprache mit den Leuten aus dem IRC diverse Versuche unternommen, das wieder hinzubekommen, allerdings nutzt Synology eine eigene Implementierung von BTRFS, was im IRC schon zu Beginn mit sowas wie "Ah, you are using synology with btrfs, so then say goodbye to your data" abgetan wurde. Am Ende sollten die User da aber Recht behalten, wir haben einige Stunden mit deren Hilfe versucht das zu fixen, ohne Erfolg. Uns wurde außerdem geraten, das Problem der linux-btrfs Mailing-Liste zu schreiben, um sowohl Hilfe als auch Feedback zu bekommen, was wir aber letzten Endes nicht getan haben.

Irgendwann um 4Uhr morgens waren wir dann an dem Punkt das wir gesagt haben, es ist nichts mehr zu machen, die vorhandenen Daten schreiben wir ab. Nun ging es also darum, das Backup von vor 14 Tagen wiederherzustellen. Da grundsätzlich schon mal die Überlegung anstand, bei dem Kunden ein High-Availability-Cluster einzurichten, haben wir an der Stelle dann ein neues RS3618xs+ bestellt, welches wir dann mit den Backups bestücken wollten. Anschließend sollte das alte RS3816xs+ formatiert und dann ein HA-Cluster eingerichtet werden. Das neue NAS kam also und wurde mit Platten bestückt. Dann haben wir das OffSite-Backup-1 ins Büro geholt, die beiden miteinander verbunden und dann 3 Tage alles was da war rückgesichert. Zuerst die kritischen Sachen (Terminalserver, Rechnungswesen etc.) und dann den Rest (sonstige VMs usw.)
Insgesamt war das schon eine interessante Erfahrung, die ich aber kein zweites mal haben möchte. Was sich aus einem einfachen "Ich kann mich mit dem Terminalserver nicht verbinden"-Ticket wird, habe ich so auch noch nicht erlebt. Die fehlenden 14 Tage bezogen sich zum Glück nur auf unkritische Dinge, die hochkritischen Sachen hatten wir alle < 24Std.
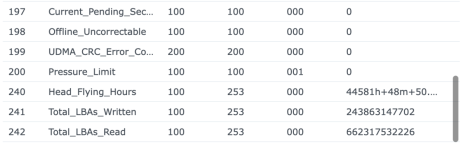
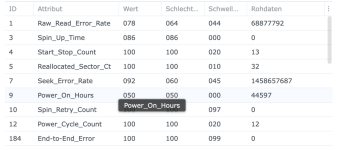
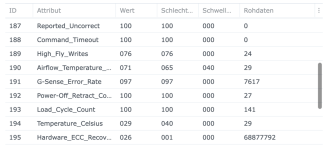
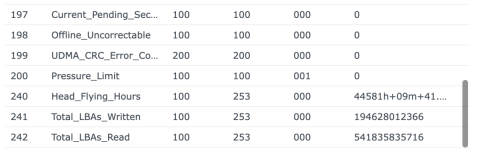
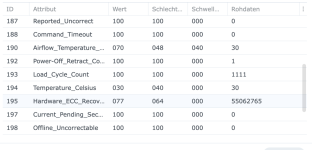
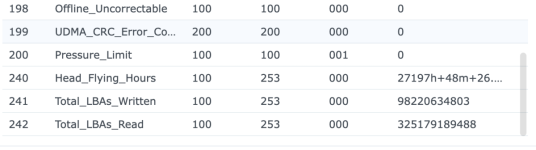
Ich/Wir sind grundsätzlich davon weg, SSD-Cache bei irgendwelchen Kunden zu verwenden - zumindest nicht mehr im Bereich wirklich kritischer Daten. Wie wir so rausgelesen haben, scheint es da ein grundsätzliches Thema mit DSM 7 zu geben, da sind wir aber nicht mehr tiefer eingestiegen und mit dem Synology-Support habe ich das auch alles nicht besprochen.
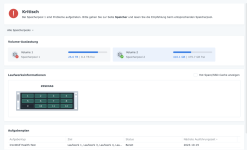
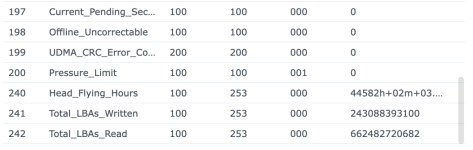
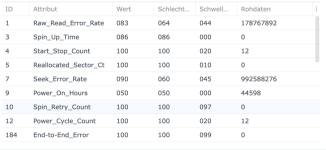
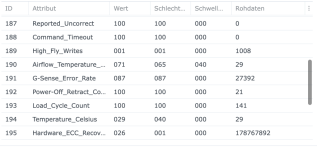
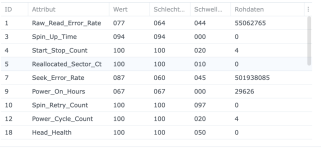
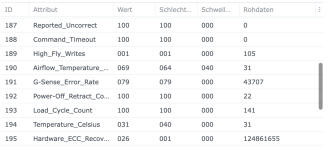
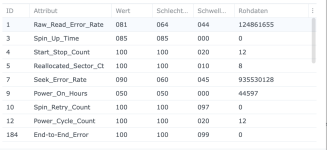
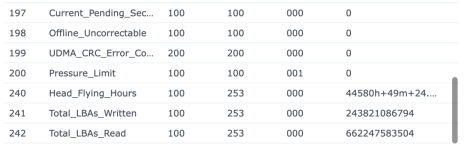
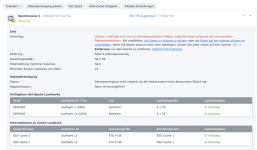
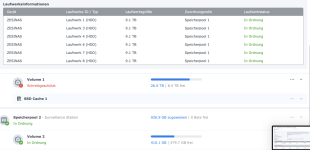
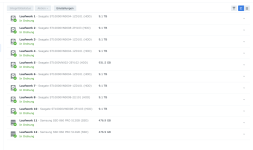
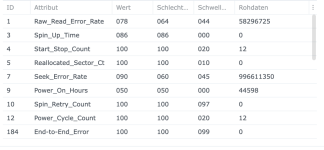
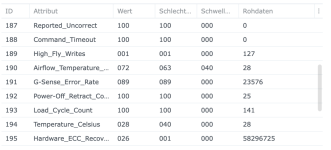
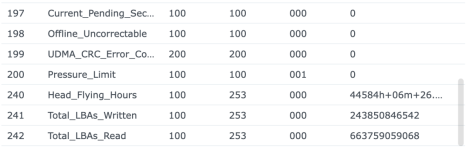
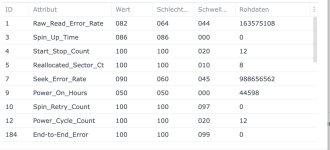
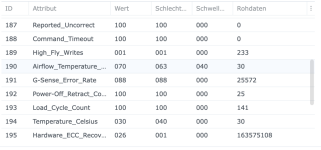
Ich habe also im Nachgang bei einigen Kunden den SSD-Cache deaktiviert und siehe da, heute morgen bekomme ich eine E-Mail, beide SSDs ausgefallen, erwartete Lebensdauer 1%... Prost Mahlzeit, aber zum Glück nicht weiter tragisch. Die Platten werden ausgebaut und das wars dann auch.
Wie dem auch sei... ich wollte das einfach noch mal ein bisschen zusammenfassen. Am Ende ist niemandem geholfen, wenn Beiträge in einem Forum im Internet immer dann aufhören, wenn jemand sein Problem gelöst hat. So kann vielleicht irgendwann irgendwer noch mal auf das Thema hier stoßen und sich einiges an Zeit und Kopfschmerzen sparen.


") .
.