Guten Morgen,
man wird geweckt mit dem engelsgleichen Piepen der Diskstation, mein Hirn schlägt gerade Purzelbäume.
Ich weiß, dass es dieses Thema öfter gibt ;-), aber ich suche gerade einordnung damit ich nicht noch mehr kaputt mache, bitte.
Im September 2022 meine DS220+ mit zwei neuen Ironwolf (ST4000VN008-2DR166), 4TB, gestartet.
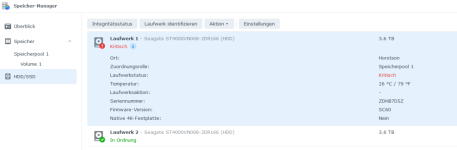
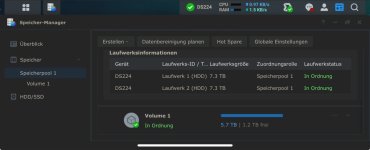
Heute morgen dann ist der Speicherpool bei Volume 1 kritisch, Volume 2 wird noch normal angezeigt. Ich habe das NAS nun erstmal heruntergefahren.
ich wäre euch sehr dankbar für eine Einordnung. Mache mich dann auf die Suche nach einer neuen Platte und Tutorials wie ich meine Daten zumindest von Volume 2 noch retten kann. Für Hinweise wäre ich auch da sehr dankbar.
Gruß
Al
man wird geweckt mit dem engelsgleichen Piepen der Diskstation, mein Hirn schlägt gerade Purzelbäume.
Ich weiß, dass es dieses Thema öfter gibt ;-), aber ich suche gerade einordnung damit ich nicht noch mehr kaputt mache, bitte.
Im September 2022 meine DS220+ mit zwei neuen Ironwolf (ST4000VN008-2DR166), 4TB, gestartet.
Heute morgen dann ist der Speicherpool bei Volume 1 kritisch, Volume 2 wird noch normal angezeigt. Ich habe das NAS nun erstmal heruntergefahren.
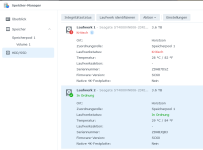
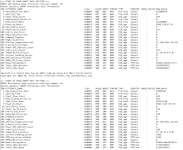
Informationen zum Laufwerk
Hersteller: Seagate
Modell: ST4000VN008-2DR166
Größe: 3.600000 TB
Seriennummer: ZDHB7D5Z
Firmware-Version: SC60
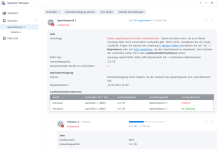
Zuordnungsrolle: Storage Pool 1
- Seht ihr einen Fehler, ich weiß noch, dass das damals ein ziemliches gesuche war, welche HDD nun für ein NAS geeignet ist und welche nicht. Vielleicht hab ich hier doch die falsche gekauft?
- Die Diskstation empfielt: "Die Anzahl fehlerhafter Sektoren auf Laufwerk 1 von DS220+ hat zugenommen. Wir empfehlen eine Datenbereinigung, um die Datenkonsistenz sicherzustellen." Kann ich das wirklich tun, ich hänge schon an meinen Daten..
- Ich gehe davon aus, dass ich die Festplatte ersetzten muss, nach nicht mal zwei Jahren... Kann ich neben die noch funktionierende Festplatte auch z.B. eine Westerndigital nutzen? (Die letzten liefen 8 Jahre ohne Fehler..) oder sollte ich dann besser beide tauschen?
- Die Speicherbereinigung/Datenbereinigung bzw. das Ironwolf-Health-Management hat bis heute keinen Fehler gefunden, kann das sein? heut jetzt auf gleich? ist ja keine SSD..
ich wäre euch sehr dankbar für eine Einordnung. Mache mich dann auf die Suche nach einer neuen Platte und Tutorials wie ich meine Daten zumindest von Volume 2 noch retten kann. Für Hinweise wäre ich auch da sehr dankbar.
Gruß
Al