@XXL1602
Im Aufgabenplaner ein Benutzerdefiniertes Script als root anlegen, Ausführungszeit kannst du dir aussuchen und den Befehl
docker exec Paperless-NGX document_exporter ../export bei Aufgabeneinstellung eintragen. Das
Paperless-NGX ist der Name meines Paperless Containers, den müsstest du auf deinen Container bzw. Stack anpassen. Hat bei mir wurnderbar funktioniert.
Damit hätte ich also die DB gesichert (wg. "webserver") gehabt, WENN es funktioniert HÄTTE?
Richtig, inklusive aller Dokumente und Vorschaubilder die in Paperless enthalten sind.
Ein Backup dient dazu, Daten vor deren Verschlust zu schützen. Welche Daten du als schützenswert erachtest ist deine Sache. Bei Paperless haben wir grob gesagt zwei "Grundarten" von Daten -> 1. Dokumente und 2. Config-Daten.
1. Dokumente: Sichern? Ja!!!
2. Config-Daten: Da kommt es auf die Art der Nutzung von Paperless an und natürlich auf deine Bereitschaft, nach dem total Verlust des Containers, den Server und die Datenbank neu auf zubauen. Nutzt du Paperless alleine und hast in einer vertretbaren Zeit, den Server neu auf gebaut, dann nicht umbedingt. Nutzt du Paperless dagegen mit der ganzen Familie oder hast over 9000 Speicherpfade, Dokumententypen, Korrespondenten und es würde eine herhebliche Zeit deines Lebens kosten, dann Ja!!!
Beispiel bei mir: Ich nutze Paperless zum Beispiel als "Sortier-Sklave" und als WebAcces für meine Dokumente. Wenn ich im Heimnetz sitze, dann arbeite ich hauptsächlich über den Explorer und den PDF-Datein direkt. Deswegen habe ich den Archiv Ordner auch auf meine Dokumenten Freigabe gemappt. Diese Freigabe wird täglich über Hyper Backup mit zwei verschienen Cloud Diensten verschlüsselt gesichert. Die Config wird nicht sichert.
Ich sehe 3 mögliche Backup-Varianten.
1. Du hast Paperless inkl. Datenbank als Stack eingerichtet. Dann den paperless-ngx via Hyper Backup weg sichern und gleich die Stack Einrichtung via yaml-Datei in den Ordner rein. Vorteil: Stack ist schnell neu erstellt und alle Datein sind vorhanden. Die Passwörter der Datenbank und des Admin-Konto von Paperless sollten nicht umbedingt im Klartext in der Docker Compose Datei rumliegen, die solltest du anderweitig aufbewahren. --> Diese Methode funktioniert bei mir eher weniger, da ich Paperless nicht als Stack laufen lasse, DB ist ein seperater Container, da noch ander Dienste den mitnutzen und der Archiv Ordner liegt niicht in dem Verzeichniss.
2. Im Aufgabenplaner täglich den Export-Befehl ausführen lassen und dann den Export-Ordner via Hyper Backup sichern. Das Stack mit Datenbank muss dann neu erstellt werden, aber die Daten können dann einfach via Import-Befehl eingelesen werden.
3. Du sicherst nur die Dokumente, egal ob der Archiv Ordner noch im Papless Verzeichniss liegt oder so wie bei mir, wo anderes liegt.
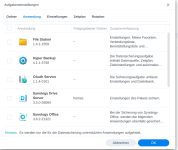
Bei der Sicherung der Anwendungen steht ja immer Dabei, was gesichert wird. Zum Beispiel beim Hyper Backup werden die Sicherungsaufgaben, Zeitpläne und alle Einstellung gesichert.
Der Ordner (Freigegebener Ordner)
NetBackup wird automatisch erstellt, wenn die
Netzwerksicherung aktiviert ist. Das ist wenn du unter "Einstellungen -> Dateidienste -> rsync" aktivierst bzw. eine entsprechne Anwendung dafür installiert hast.