Hallo!
Vielen Dank für das Willkommen und Eure Antworten.
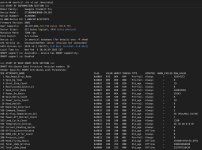
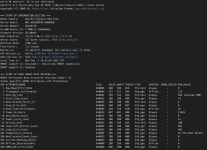
Es sieht also eigentlich so aus, dass beide Platten in Ordnung sind. Seht Ihr irgendeine Chance, den Zustand der Platten und dann des Speicherpools wieder auf "normal" zu bekommen?
Ich habe hier auch noch den Output von dmesg mit rangepackt.
ash-4.4# dmesg -He
[Feb 5 12:46] ata1.00 (slot 4): status: { DRDY }
[ +0.005168] ata1 (slot 4): hard resetting link
[ +0.197699] ata2 (slot 5): SATA link up 6.0 Gbps (SStatus 133 SControl 300)
[ +0.055385] ata2.00 (slot 5): disabling queued TRIM support
[ +0.033260] ata2.00 (slot 5): disabling queued TRIM support
[ +0.000009] ata2.00 (slot 5): configured for UDMA/133
[ +0.005859] ata2 (slot 5): EH complete
[ +0.006102] DMAR: DRHD: handling fault status reg 3
[ +0.005643] DMAR: DMAR:[DMA Read] Request device [00:12.0] fault addr 81303fc000
DMAR:[fault reason 04] Access beyond MGAW
[ +0.014450] ata2.00 (slot 5): exception Emask 0x60 SAct 0x4000000 SErr 0x800 action 0x6 frozen
[ +0.009822] ata2.00 (slot 5): irq_stat 0x20000000, host bus error
[ +0.007005] ata2 (slot 5): SError: { HostInt }
[ +0.005161] ata2.00 (slot 5): failed command: WRITE FPDMA QUEUED
[ +0.006915] ata2.00 (slot 5): cmd 61/00:d0:60:54:46/05:00:df:03:00/40 tag 26 ncq 655360 out
res 40/00:d0:60:54:46/00:00:df:03:00/40 Emask 0x60 (host bus error)
[ +0.018747] ata2.00 (slot 5): status: { DRDY }
[ +0.005168] ata2 (slot 5): hard resetting link
[ +0.159467] ata1 (slot 4): SATA link up 6.0 Gbps (SStatus 133 SControl 300)
[ +0.012714] ata1.00 (slot 4): disabling queued TRIM support
[ +0.007428] ata1.00 (slot 4): disabling queued TRIM support
[ +0.000005] ata1.00 (slot 4): configured for UDMA/133
[ +0.005859] sd 0:0:0:0: [sata1] tag#2 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
[ +0.009530] sd 0:0:0:0: [sata1] tag#2 Sense Key : 0x5 [current] [descriptor]
[ +0.008169] sd 0:0:0:0: [sata1] tag#2 ASC=0x21 ASCQ=0x4
[ +0.006128] sd 0:0:0:0: [sata1] tag#2 CDB: opcode=0x8a 8a 00 00 00 00 03 df fa 74 60 00 00 05 00 00 00
[ +0.010595] blk_update_request: I/O error, dev sata1, sector in range 16642633728 + 0-2(12)
[ +0.009528] write error, md6, sata1p5 index [0], sector 16621376896 [raid1_end_write_request]
[ +0.009724] md_error: sata1p5 is being to be set faulty
[ +0.006034] raid1: Disk failure on sata1p5, disabling device.
Operation continuing on 1 devices
[ +0.011861] write error, md6, sata1p5 index [0], sector 16621377000 [raid1_end_write_request]
[ +0.009723] write error, md6, sata1p5 index [0], sector 16621377024 [raid1_end_write_request]
[ +0.009722] write error, md6, sata1p5 index [0], sector 16621377128 [raid1_end_write_request]
[ +0.009722] write error, md6, sata1p5 index [0], sector 16621377152 [raid1_end_write_request]
[ +0.009714] write error, md6, sata1p5 index [0], sector 16621377256 [raid1_end_write_request]
[ +0.009732] write error, md6, sata1p5 index [0], sector 16621377280 [raid1_end_write_request]
[ +0.009724] write error, md6, sata1p5 index [0], sector 16621377384 [raid1_end_write_request]
[ +0.009720] write error, md6, sata1p5 index [0], sector 16621377408 [raid1_end_write_request]
[ +0.009723] write error, md6, sata1p5 index [0], sector 16621377512 [raid1_end_write_request]
[ +0.009716] write error, md6, sata1p5 index [0], sector 16621377536 [raid1_end_write_request]
[ +0.009724] write error, md6, sata1p5 index [0], sector 16621377640 [raid1_end_write_request]
[ +0.009715] write error, md6, sata1p5 index [0], sector 16621377664 [raid1_end_write_request]
[ +0.009725] write error, md6, sata1p5 index [0], sector 16621377768 [raid1_end_write_request]
[ +0.009714] write error, md6, sata1p5 index [0], sector 16621377792 [raid1_end_write_request]
[ +0.009727] write error, md6, sata1p5 index [0], sector 16621377896 [raid1_end_write_request]
[ +0.009728] write error, md6, sata1p5 index [0], sector 16621377920 [raid1_end_write_request]
[ +0.009724] write error, md6, sata1p5 index [0], sector 16621378024 [raid1_end_write_request]
[ +0.009761] write error, md6, sata1p5 index [0], sector 16621378048 [raid1_end_write_request]
[ +0.009753] write error, md6, sata1p5 index [0], sector 16621378152 [raid1_end_write_request]
[ +0.009755] ata1 (slot 4): EH complete
[ +0.034331] write error, md6, sata1p5 index [0], sector 764598528 [raid1_end_write_request]
[ +0.009549] write error, md6, sata1p5 index [0], sector 763550144 [raid1_end_write_request]
[ +0.009569] write error, md6, sata1p5 index [0], sector 764598720 [raid1_end_write_request]
[ +0.009607] ata2 (slot 5): SATA link up 6.0 Gbps (SStatus 133 SControl 300)
[ +0.051598] ata2.00 (slot 5): disabling queued TRIM support
[ +0.033282] ata2.00 (slot 5): disabling queued TRIM support
[ +0.000006] ata2.00 (slot 5): configured for UDMA/133
[ +0.005868] sd 1:0:0:0: [sata2] tag#26 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
[ +0.009628] sd 1:0:0:0: [sata2] tag#26 Sense Key : 0x5 [current] [descriptor]
[ +0.008254] sd 1:0:0:0: [sata2] tag#26 ASC=0x21 ASCQ=0x4
[ +0.006233] sd 1:0:0:0: [sata2] tag#26 CDB: opcode=0x8a 8a 00 00 00 00 03 df 46 54 60 00 00 05 00 00 00
[ +0.010694] blk_update_request: I/O error, dev sata2, sector in range 16630829056 + 0-2(12)
[ +0.009529] write error, md6, sata2p5 index [1], sector 16621376896 [raid1_end_write_request]
[ +0.009715] md_error: sata2p5 is being to be set faulty
[ +0.006037] write error, md6, sata2p5 index [1], sector 16621377000 [raid1_end_write_request]