- Registriert
- 04. Jan. 2012
- Beiträge
- 5.963
- Reaktionspunkte
- 1.719
- Punkte
- 234
Ich kann ja nur für mich sprechen:
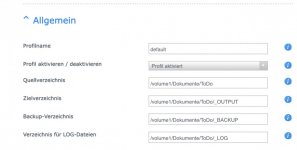
Mein Scanner scannt die Dokumente und legt sie gleich via FTP auf dem NAS in den Eingangsordner ab. 1x stündlich läuft synOCR, macht die Texterkennung und arbeitet die Regeln zur Umbenennung und Einsortierung ab. Der Zielordner wird bei mir durch Synology Drive mit den Clients abgeglichen.
Mein Scanner scannt die Dokumente und legt sie gleich via FTP auf dem NAS in den Eingangsordner ab. 1x stündlich läuft synOCR, macht die Texterkennung und arbeitet die Regeln zur Umbenennung und Einsortierung ab. Der Zielordner wird bei mir durch Synology Drive mit den Clients abgeglichen.