
So, wie angekündigt ein Feedback zum Editor. Er funktioniert und war und ist bis jetzt eine mega Hilfe. Alleine schon die Regeln übersichtlich in Excel zu bearbeiten und ggf. Filtern zu können ist genial!
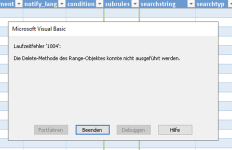
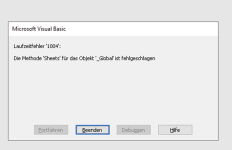
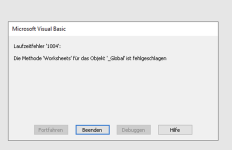
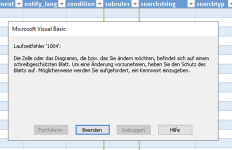
Schwierigkeiten hatte ich allerdings mit dem Trustcenter, auch funktionierts nach dem Update leider nicht mehr. Der Konfigurator öffnet sich dann nicht mehr, anklicken der verschiedenen Schaltflächen führt zu diversen Laufzeitfehlern. Ich habe leider nicht dran gedacht rechtzeitig alle Fehler zu dokumentieren ein paar Screenhots habe ich allerdings und hänge sie hier an. Ich kann nur nicht sagen ob die Fehler an meiner Bedienung, einer Konfiguration oder an sonst einem Bug liegen.
Nach dem ich den Editor durch löschen verschiedener Dateien in den AppData Verzeichnissen, wieder zum laufen gebracht habe, hatte ich die Updates nicht mehr durchgeführt und ausgeschaltet. (meine Version 1.05.00) Damit konnte ich die letzten Tage schon gut arbeiten.
Bis jetzt habe ich allerdings nur meine bereits vorhandene YAML Datei entsprechend dem Aufbau bzw. der Logik des Editors angepasst und zur weiteren Bearbeitung importiert. Die Logik des Konfigurators mit Verwendung der Kategorien habe ich verstanden jedoch bis jetzt nur 2 oder 3 komplett neue Regeln damit angelegt da ja schon eine Basis an Regeln vorhanden war.
Meine Fokus lag bisher vor allem darauf die vorhandenen Regeln weiter zu optimieren gerade in Bezug aufs Taggens bzw. Umbenennen unter Verwendung von Regex Ausdrücken, diese Möglichkeit kannte ich noch nicht oder war zum damaligen Zeitpunkt noch nicht implementiert.
Im Prinzip wurden im Nachgang einige Einzelregeln ergänzt und vorhanden nochmals modifiziert. Der Großteil entspricht nun deiner Empfehlung aus obigem Post somit auch der Logik die sich aus dem Konfigurator ergibt. Wenn man es verstanden hat macht das so auf jeden Fall Sinn, zumindest ist das meine bisherige Erkenntnis. Ansonsten hat mir funktional am Configurator bisher noch nichts gefehlt noch habe ich etwas vermisst, einfach Klasse.
Des Weiteren hatte ich mich auch lange mit dem Thema Betreff als Tag wie hier im Post #16 beschäftigt. Grundsätzlich habe ich eine Regex gebastelt die für mich in den meisten Fällen bis jetzt funktioniert hat. So ganz sauber oder optimal ist diese laut Regextester noch nicht und führt auch je nach länge des Textes zum "Catastrophic Backtracking" Ich habe kein Plan wie die REGEX aussehen müsste dass diese wirklich korrekt ist und mir den Text/Inhalt zwischen Leerzeile und z.B. "Sehr geehrter...." ausgibt. Auch hatte ich durch Zufall einen Fehler dass im Betreff ein % vor kam und in den Dateinamen geschrieben wurde, damit hat dann die Diskstation ein Problem und musste umbenannt werden. Wie und an welcher Stelle könnte ich solche sonder Zeichen ausließen, geht das?
hier mal meine Regex
Dieserfunktioniert auch bei meinem bisherigen längsten Betreff mit 5 Zeilen wobei ich eigentlich nur die Oberste Zeile benötigen würde, ich habe hier allerdings festgestellt dass der Tag automatisch durch synOCR??? gekürzt wird.
Besten Dank schonmal Vorab!
Chris
Schwierigkeiten hatte ich allerdings mit dem Trustcenter, auch funktionierts nach dem Update leider nicht mehr. Der Konfigurator öffnet sich dann nicht mehr, anklicken der verschiedenen Schaltflächen führt zu diversen Laufzeitfehlern. Ich habe leider nicht dran gedacht rechtzeitig alle Fehler zu dokumentieren ein paar Screenhots habe ich allerdings und hänge sie hier an. Ich kann nur nicht sagen ob die Fehler an meiner Bedienung, einer Konfiguration oder an sonst einem Bug liegen.
Nach dem ich den Editor durch löschen verschiedener Dateien in den AppData Verzeichnissen, wieder zum laufen gebracht habe, hatte ich die Updates nicht mehr durchgeführt und ausgeschaltet. (meine Version 1.05.00) Damit konnte ich die letzten Tage schon gut arbeiten.
Bis jetzt habe ich allerdings nur meine bereits vorhandene YAML Datei entsprechend dem Aufbau bzw. der Logik des Editors angepasst und zur weiteren Bearbeitung importiert. Die Logik des Konfigurators mit Verwendung der Kategorien habe ich verstanden jedoch bis jetzt nur 2 oder 3 komplett neue Regeln damit angelegt da ja schon eine Basis an Regeln vorhanden war.
Meine Fokus lag bisher vor allem darauf die vorhandenen Regeln weiter zu optimieren gerade in Bezug aufs Taggens bzw. Umbenennen unter Verwendung von Regex Ausdrücken, diese Möglichkeit kannte ich noch nicht oder war zum damaligen Zeitpunkt noch nicht implementiert.
Im Prinzip wurden im Nachgang einige Einzelregeln ergänzt und vorhanden nochmals modifiziert. Der Großteil entspricht nun deiner Empfehlung aus obigem Post somit auch der Logik die sich aus dem Konfigurator ergibt. Wenn man es verstanden hat macht das so auf jeden Fall Sinn, zumindest ist das meine bisherige Erkenntnis. Ansonsten hat mir funktional am Configurator bisher noch nichts gefehlt noch habe ich etwas vermisst, einfach Klasse.
Des Weiteren hatte ich mich auch lange mit dem Thema Betreff als Tag wie hier im Post #16 beschäftigt. Grundsätzlich habe ich eine Regex gebastelt die für mich in den meisten Fällen bis jetzt funktioniert hat. So ganz sauber oder optimal ist diese laut Regextester noch nicht und führt auch je nach länge des Textes zum "Catastrophic Backtracking" Ich habe kein Plan wie die REGEX aussehen müsste dass diese wirklich korrekt ist und mir den Text/Inhalt zwischen Leerzeile und z.B. "Sehr geehrter...." ausgibt. Auch hatte ich durch Zufall einen Fehler dass im Betreff ein % vor kam und in den Dateinamen geschrieben wurde, damit hat dann die Diskstation ein Problem und musste umbenannt werden. Wie und an welcher Stelle könnte ich solche sonder Zeichen ausließen, geht das?
hier mal meine Regex
Code:
(?i)(?<=)(\N+\n|\S)(\N+\n|\S)\N+\S?(?=\n*(Sehr geehrte.|Guten Tag|Hallo Frau|Liebe Mitarbeiter.*\s))Dieserfunktioniert auch bei meinem bisherigen längsten Betreff mit 5 Zeilen wobei ich eigentlich nur die Oberste Zeile benötigen würde, ich habe hier allerdings festgestellt dass der Tag automatisch durch synOCR??? gekürzt wird.
Code:
service@sparkassenversicherung.de
Mannheim, 02.10.2015
Wachstum des Versicherungsschutzes
SV Rentenversicherung Nr. 54321
Bisherige Versicherungs-Nr. 12345
Versicherungsnehmer und versicherte Person:
Name, Straße 99,54321 Stadt
Sehr geehrter Herr....
das zu Ihrer Versicherung vereinbarte Wachstum der Beiträge bewirkt, dass sich auch derBesten Dank schonmal Vorab!
Chris

")




") aber Hauptsache es funktioniert! Habs jedoch noch nicht getestet.
aber Hauptsache es funktioniert! Habs jedoch noch nicht getestet.





