
Ich habe eine Frage betreffend Nextcloud und synocr.
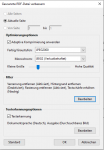
In ein einfaches Verzeichnis auf der Diskstation ist ohne Probleme zu speichern.
Ich möchte jedoch das ganze in ein Verzeichnis eines Benutzers in Nextcloud einlesen.
Das Verzeichnis ist jedoch durch besodnere Rechte von Nextcloud belegt, so dass man wohl nicht schreiben kann.
Möglich wäre vielleicht eine Webdav Verbindung. Ist das möglich ? Mit Angabe Cloud URL mit Anmeldenamen und Passwort und Auswahl des Verzeichnisses.
Warum ich das Frage. Files die man nicht über das Hochladen in Nextcloud gebracht hat, werden von der Volltextsuche ignoriert.
Danke..
Viele Grüße
micky1067
In ein einfaches Verzeichnis auf der Diskstation ist ohne Probleme zu speichern.
Ich möchte jedoch das ganze in ein Verzeichnis eines Benutzers in Nextcloud einlesen.
Das Verzeichnis ist jedoch durch besodnere Rechte von Nextcloud belegt, so dass man wohl nicht schreiben kann.
Möglich wäre vielleicht eine Webdav Verbindung. Ist das möglich ? Mit Angabe Cloud URL mit Anmeldenamen und Passwort und Auswahl des Verzeichnisses.
Warum ich das Frage. Files die man nicht über das Hochladen in Nextcloud gebracht hat, werden von der Volltextsuche ignoriert.
Danke..
Viele Grüße
micky1067

")


 )
)





