
synOCR synOCR - GUI für OCRmyPDF
- Ersteller geimist
- Erstellt am
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
So, meine Freunde der texterkannten PDFs:
Weil die ToDo-Liste von alleine ja nicht kürzer, sondern eher länger wird, habe ich mal versucht, dem etwas entgegenzusetzen.
Das Ganze findet ihr hier als Prerelease für die kommende Version 1.2.0 auf meinem Server (für DSM6 & DSM7): https://geimist.eu/synOCR/
➜ SPK DSM6
➜ SPK DSM7
Weil die ToDo-Liste von alleine ja nicht kürzer, sondern eher länger wird, habe ich mal versucht, dem etwas entgegenzusetzen.
Das Ganze findet ihr hier als Prerelease für die kommende Version 1.2.0 auf meinem Server (für DSM6 & DSM7): https://geimist.eu/synOCR/
➜ SPK DSM6
➜ SPK DSM7
Was gibt's Neues:
| BUGFIXES: | |
| - Das Anlegen der benötigten Benutzergruppe 'docker' war nicht möglich, wenn bereits eine gleichnamige Gruppe existierte (DSM7 only) | |
| - RegEx mit lookahead / lookbehind für tag-Namen war nicht möglich | |
| - einige Fehlerbehebungen (thx to @Tommes ) | |
| VERBESSERUNGEN: | |
| - Behandlung von Sonderzeichen verbessert Bitte testet besonders die OCR-Parameter, sofern ihr euch da ausgetobt habt. @symax (das Problem von #1939 konnte ich noch nicht lösen, aber die Werte werden jetzt scheinbar korrekt an ocrmypdf übergeben) | |
| - Bereinigung von unbenutzten (ersetzten) Docker-Images | |
| - Cronjob löschen, der mit synOCR bei DSM6 erzeugt wurde (das geht inzwischen nicht mehr über den Sicherheitsberater) | |
| - DSM-Benachrichtigungen funktionieren wieder | |
| - DSM-Benachrichtigungen: Liste aller möglichen Benutzer in der GUI | |
| - Indikator für die Gültigkeit der Verzeichnisse in der GUI | |
| - die Reihenfolge der Tags kann nun festgelegt werden | |
| Kriterium ist die alphabetische Sortierung der Regelnamen in der YAML-Datei @s-tyle @reneh | |
| NEUES: | |
| - Umbenennungsparameter für das Jahr kann nun 2- oder 4-stellig sein | |
§yocr2 §yocr4 §ynow2 §ynow4 §ysource2 §ysource4 | |
| - Zieldateien können in nach Jahr benannte Ordner verschoben werden (Auswahl in der GUI) @TJ. | |
| - Zieldateien können in nach Jahr/Monat benannten Ordnern abgelegt werden (Auswahl in der GUI) | |
| - Die Anzahl der Backupdateien kann nun begrenzt werden (Tage oder Anzahl) @peterhoffmann |
Zuletzt bearbeitet:
Hallo in die Runde.
Ich hätte eine Frage zur Sicherheit bzgl. zu ignorierender Datumsangaben.
In der Config von "Daten ignorieren" standen bei mir schon zwei Datumsangaben drin, die meines Wissens nicht von mir stammen (2021-02-29 und 2020-11-31). Kann das sein?
Ich wollte nun ein oder zwei Daten hinzufügen die beim ocr ignoriert werden sollen, Schnell einmal mit der Maus über dem i gehovered und da steht mit LEERZEICHEN getrennt. Die eingegebenen Daten bei mir sind aber mit SEMIKOLON getrennt. 2021-02-29;2020-11-31
Geht somit beides oder sind die Daten bei mir falsch eingetragen?
Info hierzu. Ich nutze schon deine Beta in DSM7.
Bei der Gelegenheit habe ich gerade auch zu deiner neuesten BETA upgedated.
Ich hätte eine Frage zur Sicherheit bzgl. zu ignorierender Datumsangaben.
In der Config von "Daten ignorieren" standen bei mir schon zwei Datumsangaben drin, die meines Wissens nicht von mir stammen (2021-02-29 und 2020-11-31). Kann das sein?
Ich wollte nun ein oder zwei Daten hinzufügen die beim ocr ignoriert werden sollen, Schnell einmal mit der Maus über dem i gehovered und da steht mit LEERZEICHEN getrennt. Die eingegebenen Daten bei mir sind aber mit SEMIKOLON getrennt. 2021-02-29;2020-11-31
Geht somit beides oder sind die Daten bei mir falsch eingetragen?
Info hierzu. Ich nutze schon deine Beta in DSM7.
Bei der Gelegenheit habe ich gerade auch zu deiner neuesten BETA upgedated.
Zuletzt bearbeitet:
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
Das sind Beispieleinträge - und wenn du genau hinschaust, wirst du feststellen, dass es sich bei beiden um ungültige Daten handelt. Sie dienen als Symbol für die Schreibweise, welche aber nicht mit Benutzerangaben in Konflikt kommen.standen bei mir schon zwei Datumsangaben drin, die meines Wissens nicht von mir stammen (2021-02-29 und 2020-11-31). Kann das sein?
Es geht beides… da steht mit LEERZEICHEN getrennt. Die eingegebenen Daten bei mir sind aber mit SEMIKOLON getrennt. Geht somit beides oder sind die Daten bei mir falsch eingetragen?
")
Zuletzt bearbeitet:
Ja das hab ich tatsächlich bemerkt das die Daten quatsch sind. Tatsächlich war dies der Grund weshalb ich mir relativ sicher war das ich die Daten nicht eigeben habe. Beim 29.02. für das Jahr 2021 hätte ich noch an einen Tippfehler meinerseits verstanden abder das der November nur 30 Tage hat das weiß ich dann doch. ")
Schön zu wissen beides geht. Tatsächlich gefällt mir das semikolon als Trennzeichen deutlich besser.
Vielen Dank für die Info und vor allem vielen Dank für das Tool. Ich bin wirklich sehr zufrieden was man damit für Zuhause erreichen kann.
Trotzdem muss man sich bei den Regeln schon gut ein paar Gedanken machen, damit die Dokumente auch vernünftig einsortiert werden, vor allem wenn Daten zweier Personen eingelesen werden. Aber Spaß macht es trotzdem und deine Hilfsbereitschaft ist wirklich überragend.
Schön zu wissen beides geht. Tatsächlich gefällt mir das semikolon als Trennzeichen deutlich besser.
Vielen Dank für die Info und vor allem vielen Dank für das Tool. Ich bin wirklich sehr zufrieden was man damit für Zuhause erreichen kann.
Trotzdem muss man sich bei den Regeln schon gut ein paar Gedanken machen, damit die Dokumente auch vernünftig einsortiert werden, vor allem wenn Daten zweier Personen eingelesen werden. Aber Spaß macht es trotzdem und deine Hilfsbereitschaft ist wirklich überragend.
Zuletzt bearbeitet von einem Moderator:
TJ.
Benutzer
- Registriert
- 29. Apr. 2021
- Beiträge
- 40
- Reaktionspunkte
- 3
- Punkte
- 14
Hi geimist,
das sind ja tolle Neuigkeiten. Danke für deine (Eure) Mühe!")
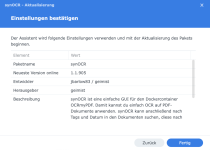
Hab's sofort runtergeladen, um es zu installieren. Kann es sein, dass in der spk noch die alte Version steckt, oder bin ich wieder zu doof? Wenn ich die spk manuelle installieren will, bekomme ich die alte Version 1.1.905 angezeigt (siehe Screenshot).
das sind ja tolle Neuigkeiten. Danke für deine (Eure) Mühe!
Hab's sofort runtergeladen, um es zu installieren. Kann es sein, dass in der spk noch die alte Version steckt, oder bin ich wieder zu doof? Wenn ich die spk manuelle installieren will, bekomme ich die alte Version 1.1.905 angezeigt (siehe Screenshot).
Anhänge
TJ.
Benutzer
- Registriert
- 29. Apr. 2021
- Beiträge
- 40
- Reaktionspunkte
- 3
- Punkte
- 14
@geimist und @tomjonsSo. Jetzt muss ich mich noch mit der Sortierung in Ordner kümmern.
Bisweilen werden die PDF ja mit der erkannten Belegnummer umbenannt.
Nun möchte ich noch: Falls im Belegfuß "Amazon"oder "Ebay" steht entsprechend in den jeweiligen Ordner sortiert wird.
Code:tagBestellnummer8: tagname: "Ihr Beleg" targetfolder: tagname_RegEx: ((?<=(^Ihr Beleg[:|;][\s]{7}){1})|(?<=(^Ihr Beleg[:|;][\s]{8}){1})|(?<=(^Ihr Beleg[:|;][\s]{9}){1}))[0-9]+ condition: all subrules: - searchstring: ((?<=(^Ihr Beleg[:|;][\s]{7}){1})|(?<=(^Ihr Beleg[:|;][\s]{8}){1})|(?<=(^Ihr Beleg[:|;][\s]{9}){1}))[0-9]+ searchtyp: contains isRegEx: true source: content casesensitive: false
Hi, ich möchte gerne dieses Thema nochmal aufgreifen, da ich vor einer ähnlichen Herausforderung stehe. Ich habe regelmäßige Dokumente (siehe Anhang), die eine laufende Nummer beinhalten und diese möchte ich in den Dateinamen einbinden.
"LfdNr", ":" und "71" sind nicht zusammenhängend, sondern einzelne Textbereiche. Habe ich da eine Chance, das mit der o.a. RegEx-Lösung die Nummer "71" auszulesen und in den Dateinamen einzubinden?
Was meint ihr?
Anhänge

- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
Prinzipiell geht das mit Lookbehind-Regex. Das hatten wir HIER schon mal ergründet. Der entscheidente Nachteil bei dieser Sache: die Anzahl der Leerzeichen muss fest definiert sein. Das macht es schwierig. Hier hilft dann nur, mehrere Möglichkeiten mit OR zu kombinieren.
In diesem Fall sind es nach LfdNr 3 Leerzeichen und nach dem Doppelpunkt 6:
In diesem Fall sind es nach LfdNr 3 Leerzeichen und nach dem Doppelpunkt 6:
(?<=(^LfdNr[\s]{3}[:|;][\s]{6}){1})[0-9]+
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
OR ist in dem Fall ein Pipe (=Mit OR Meist du dieses "lange Ding" was @tomjons auch genutzt hat, oder?
| ). Man kombiniert also mehrere Möglichkeiten. Ein Beispiel hatte ich HIER gezeigt.Wieviel Leerzeichen jetzt bei dir von OCR interpretiert werden, müsste man im RAW-Text nachsehen (findest du im Log-Ordner bei erweitertem Loglevel 2). Die 3 und 6 Leerzeichen waren jetzt nur ein Beispiel und ins Blaue geraten.Wie kommst du auf 3 und 6 Leerzeichen?
superuser_
Benutzer
- Registriert
- 09. Jan. 2022
- Beiträge
- 1
- Reaktionspunkte
- 0
- Punkte
- 1
Guten Tag!
Erstmal möchte ich die tolle Funktionalität dieser Anwendung hervorheben! Vielen Dank dafür!
Allerdings habe ich festgestellt, dass lediglich die .pdf Dateien im Hauptordner gescannt werden und nicht welche, welche sich im Unterordner befinden. Wie kann ich das ändern?
Ich muss auch die PDFs im Unterordner scannen.
VG
Erstmal möchte ich die tolle Funktionalität dieser Anwendung hervorheben! Vielen Dank dafür!
Allerdings habe ich festgestellt, dass lediglich die .pdf Dateien im Hauptordner gescannt werden und nicht welche, welche sich im Unterordner befinden. Wie kann ich das ändern?
Ich muss auch die PDFs im Unterordner scannen.
VG
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
Herzlich willkommen hier im Forum, @superuser_
Das ist richtig. Für den alltäglich Workflow (ein Scanner speichert in den Input-Ordner), ist ja die Beachtung einer Hierarchie auch nicht nötig. In der Regel besteht dieser use case bei der Ersteinrichtung. Für diesen Zweck gibt ein ein Hilfsskript, welches man konfigurieren und dann 1x aufrufen muss. Anschließend lässt man synOCR seine Arbeit verrichten und ruft abschließend noch einmal das Hilfsskript auf.
Hier wirst du fündig: https://git.geimist.eu/geimist/synOCR/src/branch/master/recursive_inputdir_workflow.sh
Wenn die Hierarchie im Ausgabeordner keine Beachtung finden muss, kann man sich natürlich auch alle PDFs einfacher zusammensuchen und in den Inputordner verschieben. Sollen in Zukunft mehrere Ordner Beachtung finden, würde ich entsprechend viele Profile anlegen.
Das ist richtig. Für den alltäglich Workflow (ein Scanner speichert in den Input-Ordner), ist ja die Beachtung einer Hierarchie auch nicht nötig. In der Regel besteht dieser use case bei der Ersteinrichtung. Für diesen Zweck gibt ein ein Hilfsskript, welches man konfigurieren und dann 1x aufrufen muss. Anschließend lässt man synOCR seine Arbeit verrichten und ruft abschließend noch einmal das Hilfsskript auf.
Hier wirst du fündig: https://git.geimist.eu/geimist/synOCR/src/branch/master/recursive_inputdir_workflow.sh
Wenn die Hierarchie im Ausgabeordner keine Beachtung finden muss, kann man sich natürlich auch alle PDFs einfacher zusammensuchen und in den Inputordner verschieben. Sollen in Zukunft mehrere Ordner Beachtung finden, würde ich entsprechend viele Profile anlegen.
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
Noch ein Prerelease (v1.1.906) für die kommende Version 1.2.0:
➜ SPK DSM6
➜ SPK DSM7
➜ SPK DSM6
➜ SPK DSM7
Was gibt's Neues (grau sind die Merkmale der vorherigen Version):
| WICHTIG ! | Mit dieser Version ist der Zeitplaner in auch in DSM6 nicht mehr in der GUI verfügbar. Bitte verwende den DSM Aufgabenplaner! Dadurch sind engere Intervalle möglich und ein späteres Upgrade auf DSM7 wird dadurch vereinfacht. |
| BUGFIXES: | - Das Anlegen der benötigten Benutzergruppe 'docker' war nicht möglich, wenn bereits eine gleichnamige Gruppe existierte (DSM7 only) |
| - RegEx mit lookahead / lookbehind für tag-Namen war nicht möglich | |
| - einige Fehlerbehebungen (thx to @Tommes ) | |
| VERBESSERUNGEN: | - Behandlung von Sonderzeichen verbessert Bitte testet besonders die OCR-Parameter, sofern ihr euch da ausgetobt habt. @symax (das Problem von #1939 konnte ich noch nicht lösen, aber die Werte werden jetzt scheinbar korrekt an ocrmypdf übergeben) |
| - Bereinigung von unbenutzten (ersetzten) Docker-Images | |
| - Cronjob löschen, der mit synOCR bei DSM6 erzeugt wurde (das geht inzwischen nicht mehr über den Sicherheitsberater) | |
| - DSM-Benachrichtigungen funktionieren wieder | |
| - DSM-Benachrichtigungen: Liste aller möglichen Benutzer in der GUI | |
| - Indikator für die Gültigkeit der Verzeichnisse in der GUI | |
| - die Reihenfolge der Tags kann nun festgelegt werden Kriterium ist die alphabetische Sortierung der Regelnamen in der YAML-Datei @s-tyle @reneh | |
| - @Tommes hat die komplette GUI auf neue Füße gestellt. Tommes und ich haben schon fleißig getestet, aber bitte kontrolliert, ob alle Formularfelder wie gewünscht funktionieren. | |
| - synOCR wurde im Paketzentrum umbenannt (synOCR DSM6 & synOCR DSM7). Ich hoffe, dass sich nach dem Veröffentlichen auf cphub.net das Handling dadurch etwas verbessert. | |
| NEUES: | - Umbenennungsparameter für das Jahr kann nun 2- oder 4-stellig sein§yocr2 §yocr4 §ynow2 §ynow4 §ysource2 §ysource4 |
| - Zieldateien können in nach Jahr benannte Ordner verschoben werden (Auswahl in der GUI) @TJ. | |
| - Zieldateien können in nach Jahr/Monat benannten Ordnern abgelegt werden (Auswahl in der GUI) | |
| - Die Anzahl der Backupdateien kann nun begrenzt werden (Tage oder Anzahl) @peterhoffmann | |
- Umbenennungsparameter §pagecount hinzugefügt (Seitenanzahl des aktuellen Dokuments) @TJ. | |
- alle Umbenennungsparameter können nun auch als Variablen in Regel basierten Pfaden (YAML-Regeldatei) verwendet werden (z.B. /Rechnungen/§yocr4 ). Ausgenommen davon ist die Variable §tit für den originalen Dokumentnamen. @TJ. |
claus_hipp
Benutzer
- Registriert
- 11. Jan. 2022
- Beiträge
- 11
- Reaktionspunkte
- 4
- Punkte
- 3
Hallo geimist,
vielen Dank für deine wirklich tolle und auch einfache zu benutzen Anwendung!!
Im Moment bin ich am Scannen meiner Unterlagen und suche noch nach dem Perfekten Dateinamen.
Was ich bisher als Verbesserungsvorschlag habe ist folgendes:
- "$pagecount_latest" als Umgebungsvariable - damit ich nur den Pagecount des aktuellen Dokuments verwenden kann - dann sehe ich gleich wie viele Seiten ein Dokument hat, noch bevor ich es öffne.
- Bei mir funktioniert der Parameter: -s nicht -> Dokumente laufen immer wieder durch die OCR
- Ein Datei Suchwort, um Dokumente von einer erneuten OCR auszuschließen. z.B. "*OCR*" im Dateinamen
- Wenn kein Datum gefunden wurde und das Dateidatum verwenden wird, das irgendwie zu kennzeichnen. Ggf. über eine konfigurierbare Umgebungsvariabel, die dann in den Dateinamen eingebaut werden kann. Scanne ich alte Dokumente aus 2016 und die bekommen das das heutige Scandatum/Datei-Erstellungsdatum ist das okay, aber ich kann diese nicht auf Anhieb unterscheiden.
Absolut großartig wäre es, wenn man die Möglichkeit hätte, über einen "Start Profil", einen Verzeichnis anzugeben, welches alle darin enthaltenen Unterordner durchläuft, Dateien OCR`ed, ggf umbenennt, aber im gleichen Verzeichnis belasst (Originaldatei kann gern ins Backupverzeichnis verschoben werden)
--> So kann man synOCR auch ganz leicht für bestehende Ordnerstrukturen nutzen.
Weiterhin vielen Dank für deine Mühe und deinen Einsatz!!!
Mit besten Grüßen
vielen Dank für deine wirklich tolle und auch einfache zu benutzen Anwendung!!
Im Moment bin ich am Scannen meiner Unterlagen und suche noch nach dem Perfekten Dateinamen.
Was ich bisher als Verbesserungsvorschlag habe ist folgendes:
- "$pagecount_latest" als Umgebungsvariable - damit ich nur den Pagecount des aktuellen Dokuments verwenden kann - dann sehe ich gleich wie viele Seiten ein Dokument hat, noch bevor ich es öffne.
- Bei mir funktioniert der Parameter: -s nicht -> Dokumente laufen immer wieder durch die OCR
- Ein Datei Suchwort, um Dokumente von einer erneuten OCR auszuschließen. z.B. "*OCR*" im Dateinamen
- Wenn kein Datum gefunden wurde und das Dateidatum verwenden wird, das irgendwie zu kennzeichnen. Ggf. über eine konfigurierbare Umgebungsvariabel, die dann in den Dateinamen eingebaut werden kann. Scanne ich alte Dokumente aus 2016 und die bekommen das das heutige Scandatum/Datei-Erstellungsdatum ist das okay, aber ich kann diese nicht auf Anhieb unterscheiden.
Absolut großartig wäre es, wenn man die Möglichkeit hätte, über einen "Start Profil", einen Verzeichnis anzugeben, welches alle darin enthaltenen Unterordner durchläuft, Dateien OCR`ed, ggf umbenennt, aber im gleichen Verzeichnis belasst (Originaldatei kann gern ins Backupverzeichnis verschoben werden)
--> So kann man synOCR auch ganz leicht für bestehende Ordnerstrukturen nutzen.
Weiterhin vielen Dank für deine Mühe und deinen Einsatz!!!
Mit besten Grüßen
TJ.
Benutzer
- Registriert
- 29. Apr. 2021
- Beiträge
- 40
- Reaktionspunkte
- 3
- Punkte
- 14
Hi @claus_hipp- "$pagecount_latest" als Umgebungsvariable - damit ich nur den Pagecount des aktuellen Dokuments verwenden kann - dann sehe ich gleich wie viele Seiten ein Dokument hat, noch bevor ich es öffne.
Macht $pagecount nicht genau das? Also, bei mir schon.
- Registriert
- 04. Jan. 2012
- Beiträge
- 5.734
- Reaktionspunkte
- 1.538
- Punkte
- 234
Vielleicht hat @claus_hipp noch die Version aus dem Paketzentrum. Aber das Feature ist jedenfalls jetzt drin.
Dazu gibt es auch schon einen ausführlichen Post.
Bei Fragen, einfach melden.
Es gibt verschiedene Textlayer. Bitte informiere dich da mal bei ocrmypdf. synOCR reicht die Parameter ja nur durch.- Bei mir funktioniert der Parameter: -s nicht -> Dokumente laufen immer wieder durch die OCR
Da dieses Szenario in der Regel nur 1x (am Anfang) eintritt, gibt es keine eingebaute Lösung. Aber ich habe dazu ein Hilfskript erstellt, welches du hier findest: https://git.geimist.eu/geimist/synOCR/src/branch/master/recursive_inputdir_workflow.shAbsolut großartig wäre es, wenn man die Möglichkeit hätte, über einen "Start Profil", einen Verzeichnis anzugeben, welches alle darin enthaltenen Unterordner durchläuft, Dateien OCR`ed, ggf umbenennt, aber im gleichen Verzeichnis belasst …
Dazu gibt es auch schon einen ausführlichen Post.
Bei Fragen, einfach melden.


Kaffeautomat
Wenn du das Forum hilfreich findest oder uns unterstützen möchtest, dann gib uns doch einfach einen Kaffee aus.
Als Dankeschön schalten wir deinen Account werbefrei.




