
Paperless-ngx Paperless-ngx – DMS via Docker auf dem NAS
- Ersteller Monacum
- Erstellt am
-
Ab sofort steht euch hier im Forum die neue Add-on Verwaltung zur Verfügung – eine zentrale Plattform für alles rund um Erweiterungen und Add-ons für den DSM.
Damit haben wir einen Ort, an dem Lösungen von Nutzern mit der Community geteilt werden können. Über die Team Funktion können Projekte auch gemeinsam gepflegt werden.
Was die Add-on Verwaltung kann und wie es funktioniert findet Ihr hier
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
- Registriert
- 28. Okt. 2020
- Beiträge
- 15.843
- Reaktionspunkte
- 6.063
- Punkte
- 589
Ist ja auch kein Ding. Watchtower kann alle Container für dich updaten.
Kannst aber auch manuell machen. Einmal Image neu pullen und fertig. Wird aber bei mehreren Containern irgendwann zu aufwendig.
Und bei dir (und vielen anderen) war ja nicht das paperless Update schuld, sondern das Update der postgres-DB, was ja nun bei dir nach "Festsetzen der Version" nicht mehr passieren sollte
Kannst aber auch manuell machen. Einmal Image neu pullen und fertig. Wird aber bei mehreren Containern irgendwann zu aufwendig.
Und bei dir (und vielen anderen) war ja nicht das paperless Update schuld, sondern das Update der postgres-DB, was ja nun bei dir nach "Festsetzen der Version" nicht mehr passieren sollte
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Ich gehe mal davon aus, dass wir hier vom Update der Datenbank reden, oder?beim letzten mal ging das update mächtig in die hose
 bei Paperless-ngx selber kannst du unbesorgt sein, was das betrifft.
bei Paperless-ngx selber kannst du unbesorgt sein, was das betrifft.
@Monacum:
zu 1. ja, zwei OCR-Texte in einem Dokument sind nicht besonders sinnvoll - außer wenn der zweite OCR Text (der den ersten überschreibt) deutlich schlecher wäre wie der erste - aber es wäre auch sehr hinderlich wenn ich in einem OCR PDF ein Stichwort suche und dann an der selben Stellen zwei Mal angezeigt bekommen, wenn der Text zwei Mal gespeichert ist am Dokument.
Und inzwischen halte ich es für sehr wahrscheinlich, dass paperless zusätzlich den OCR Text auch in der Datenbank ablegt - sonst wäre eine Volltextsuche so gut wie unmöglich.
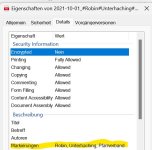
zu 3. erneuter Versuch das Bild1 anzuhängen, ja das sind Attribute der Datei. Schade, dass paperless seine tags nicht auch als Atribute an der archived Datei speichert, sowie schon bestehende Atribute aus der Originaldatei nutzen kann (und wenn ich mir was wünschen dürfte, sollte paperless das "date created" als "date modified" ebenfalls an der archived Datei speichern). Das würde die einfache Nutzung der wichtgsten Metadaten langfristig garantieren und untrennbar mit der Quelle verbinden. Denn jedes DMS ist nach zehn Jahren möglicherweise und nach zwanzig Jahren wahrscheinlich nicht mehr am Markt. Die PDFs dagegen werden wahrscheinlich viele Jahrezehnte nutzbar sein (jetzt immerhin schon 31 Jahre) - und das wäre gerade in der Ahnenforschung sehr wünschenswert, da reden wir von Nutzung für einigen Generationen.
Auf jeden Fall hast Du mir schon sehe geholfen und ich werde wohl paperless bald installieren. Und mittelfristig versuchen eigene Mechanismen zu entwickeln, wie ich die wichtgsten Metadaten (also date created, tags und der orginale Dateiname) an die archived Dateien bekomme - vielleicht auch noch an die orignal Dateien.
PS: wobei ich vermutlich auf 2.0 warten sollten, um nicht gleich am Anfang einen komplizerten Upgrade machen zu müssen.
zu 1. ja, zwei OCR-Texte in einem Dokument sind nicht besonders sinnvoll - außer wenn der zweite OCR Text (der den ersten überschreibt) deutlich schlecher wäre wie der erste - aber es wäre auch sehr hinderlich wenn ich in einem OCR PDF ein Stichwort suche und dann an der selben Stellen zwei Mal angezeigt bekommen, wenn der Text zwei Mal gespeichert ist am Dokument.
Und inzwischen halte ich es für sehr wahrscheinlich, dass paperless zusätzlich den OCR Text auch in der Datenbank ablegt - sonst wäre eine Volltextsuche so gut wie unmöglich.
zu 3. erneuter Versuch das Bild1 anzuhängen, ja das sind Attribute der Datei. Schade, dass paperless seine tags nicht auch als Atribute an der archived Datei speichert, sowie schon bestehende Atribute aus der Originaldatei nutzen kann (und wenn ich mir was wünschen dürfte, sollte paperless das "date created" als "date modified" ebenfalls an der archived Datei speichern). Das würde die einfache Nutzung der wichtgsten Metadaten langfristig garantieren und untrennbar mit der Quelle verbinden. Denn jedes DMS ist nach zehn Jahren möglicherweise und nach zwanzig Jahren wahrscheinlich nicht mehr am Markt. Die PDFs dagegen werden wahrscheinlich viele Jahrezehnte nutzbar sein (jetzt immerhin schon 31 Jahre) - und das wäre gerade in der Ahnenforschung sehr wünschenswert, da reden wir von Nutzung für einigen Generationen.
Auf jeden Fall hast Du mir schon sehe geholfen und ich werde wohl paperless bald installieren. Und mittelfristig versuchen eigene Mechanismen zu entwickeln, wie ich die wichtgsten Metadaten (also date created, tags und der orginale Dateiname) an die archived Dateien bekomme - vielleicht auch noch an die orignal Dateien.
PS: wobei ich vermutlich auf 2.0 warten sollten, um nicht gleich am Anfang einen komplizerten Upgrade machen zu müssen.
Anhänge
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Das Update der Paperless-Versionen ist untereinander kein Problem, Schwierigkeiten machen eigentlich „nur“ die Major-Updates von PostgreSQL, wenn man da die Version fixiert, ist das also auch kein Problem. Oder anders: Auf die Veröffentlichung von v2 musst du deswegen nicht warten.
Hast übrigens recht, der Text ist in der db gespeichert.
Hast übrigens recht, der Text ist in der db gespeichert.
Hallo Zusammen.
Hat jmd. von Euch eine Idee, warum bei meiner paperless Installation Umlaute (über den Karteireiter Inhalt) nicht korrekt angezeigt werden? Lasse ich OCR von paperless durchführen sind die Umlaute korrekt vorhanden. Wenn jedoch OCR über eine externe App (quickscan, scanner pro, adobe) durchgeführt wird, sind diese nicht korrekt dargestellt.
EDIT: Als Zusatzhinweis, über "Universal Search" werden in der Originaldatei die Texte korrekt indiziert und auch entsprechend gefunden (mit Umlaut)...
Danke für Eure Hinweise,
Marco
Hat jmd. von Euch eine Idee, warum bei meiner paperless Installation Umlaute (über den Karteireiter Inhalt) nicht korrekt angezeigt werden? Lasse ich OCR von paperless durchführen sind die Umlaute korrekt vorhanden. Wenn jedoch OCR über eine externe App (quickscan, scanner pro, adobe) durchgeführt wird, sind diese nicht korrekt dargestellt.
EDIT: Als Zusatzhinweis, über "Universal Search" werden in der Originaldatei die Texte korrekt indiziert und auch entsprechend gefunden (mit Umlaut)...
Danke für Eure Hinweise,
Marco
Anhänge

Zuletzt bearbeitet:
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Ich kann dir leider nicht sagen, woran das liegt, außer dass ich mir vorstellen könnte, dass es an einem anderen verwendeten Zeichensatz in einer deiner verwendeten Apps liegt. Um das ganze aber zu verhindern, könntest du folgenden Parameter in deine Konfiguration mit aufnehmen:
Und dann schaust du einfach mal, wie die Ergebnisse sind.
Danke, aber das möchte ich eigentlich vermeiden, da die Erkennung über die Apps schon merklich besser (und auch deutlich schneller) ist. Ich habe mal in das Protokoll des Containers geschaut. Kann es etwas damit:
etwas zu tun haben? Normal nutzt er C.UTF-8, im Container ist wohl auch nur das und POSIX aktiv auf der DS aber auch die de_DE...
Wie bekomme ich denn die richtige Sprache in den Container?
| perl: warning: Setting locale failed. |
| perl: warning: Please check that your locale settings: |
| LANGUAGE = (unset), |
| LC_ALL = (unset), |
| LANG = "de_DE.UTF-8" |
| are supported and installed on your system. |
| perl: warning: Falling back to the standard locale ("C"). |
etwas zu tun haben? Normal nutzt er C.UTF-8, im Container ist wohl auch nur das und POSIX aktiv auf der DS aber auch die de_DE...
Wie bekomme ich denn die richtige Sprache in den Container?
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Das ist der Befehl direkt über dem, den ich dir eben geschickt habe:
Default ist hier „eng“ für die englische Sprache. Ob das was ändert, kann ich dir aber nicht sagen, musst du ausprobieren.
Default ist hier „eng“ für die englische Sprache. Ob das was ändert, kann ich dir aber nicht sagen, musst du ausprobieren.
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Paperless-ngx v2.0.0
Repository: paperless-ngx/paperless-ngx · Tag: v2.0.0 · Commit: c075642 · Released by: github-actions[bot]paperless-ngx 2.0.0
Breaking Changes
- Breaking: Rename the environment variable for self-signed email certificates @stumpylog (#4346)
- Breaking: Drop support for Python 3.8 @stumpylog (#4156)
- Breaking: Remove ARMv7 building of the Docker image @stumpylog (#3973)
Notable Changes
- Feature: consumption templates @shamoon (#4196)
- Feature: Share links @shamoon (#3996)
- Enhancement: Updates the underlying image to use Python 3.11 @stumpylog(#4150)
Features
- Feature: compact notifications @shamoon(#4545)
- Chore: Backend bulk updates @stumpylog(#4509)
- Feature: Hungarian translation @shamoon(#4552)
- Chore: API support for id args for documents & objects @shamoon (#4519)
- Feature: Add Bulgarian translation @shamoon (#4470)
- Feature: Audit Trail @nanokatz (#4425)
- Feature: Add ahead of time compression of the static files for x86_64 @stumpylog(#4390)
- Feature: sort sidebar views @shamoon(#4381)
- Feature: Switches to a new client to handle communication with Gotenberg @stumpylog (#4391)
- barcode logic: strip non-numeric characters from detected ASN string @queaker (#4379)
- Feature: Include more updated base tools in Docker image @stumpylog (#4319)
- CI: speed-up frontend tests on ci @shamoon (#4316)
- Feature: password reset @shamoon(#4289)
- Enhancement: dashboard improvements, drag-n-drop reorder dashboard views @shamoon (#4252)
- Feature: Updates Django to 4.2.5 @stumpylog (#4278)
- Enhancement: settings reorganization & improvements, separate admin section @shamoon (#4251)
- Feature: consumption templates @shamoon (#4196)
- Enhancement: support default permissions for object creation via frontend @shamoon(#4233)
- Fix: Set permissions before declaring volumes for rootless @stumpylog (#4225)
- Enhancement: bulk edit object permissions @shamoon (#4176)
- Enhancement: Allow the user the specifiy the export zip file name @stumpylog(#4189)
- Feature: Share links @shamoon (#3996)
- Chore: update docker image and ci to node 20 @shamoon (#4184)
- Fix: Trim unneeded libraries from Docker image @stumpylog (#4183)
- Feature: New management command for fuzzy matching document content @stumpylog (#4160)
- Enhancement: Updates the underlying image to use Python 3.11 @stumpylog(#4150)
- Enhancement: frontend better handle slow backend requests @shamoon (#4055)
- Chore: update docker image & ci testing node to v18 @shamoon (#4149)
- Enhancement: Improved error notifications @shamoon (#4062)
- Feature: Official support for Python 3.11 @stumpylog (#4146)
- Enhancement: Add Afrikaans, Greek & Norwegian languages @shamoon (#4088)
- Enhancement: add task id to pre/post consume script as env @andreheuer(#4037)
- Enhancement: update bootstrap to v5.3.1 for backend static pages @shamoon(#4060)
Bug Fixes
- Fix: Add missing spaces to help string in document_retagger @joouha (#4674)
- Fix: Typo invalidates precondition for doctype, resulting in Exception @ArminGruner (#4668)
- Fix: Miscellaneous visual fixes in v2.0.0-beta.rc1 2 @shamoon (#4635)
- Fix: Delay consumption after MODIFY inotify events @frozenbrain (#4626)
- Documentation: Add note that trash dir must exist @shamoon (#4608)
- Fix: Miscellaneous v2.0 visual fixes @shamoon (#4576)
- Fix: Force UTF-8 for exporter manifests and don't allow escaping @stumpylog(#4574)
- Fix: plain text preview overflows @shamoon (#4555)
- Fix: add permissions for custom fields with migration @shamoon (#4513)
- Fix: visually hidden text breaks delete button wrap @shamoon (#4462)
- Fix: API statistics document_file_type_counts return type @shamoon (#4464)
- Fix: Always return a list for audit log check @shamoon (#4463)
- Fix: Only create a Correspondent if the email matches rule filters @stumpylog(#4431)
- Fix: Combination of consume template with recursive tagging @stumpylog (#4442)
- Fix: replace drag drop & clipboard deps with angular cdk @shamoon (#4362)
- Fix: update document modified time on note creation / deletion @shamoon(#4374)
- Fix: Updates to latest imap_tools which includes fix for the meta charset in HTML content @stumpylog (#4355)
- Fix: Missing creation of a folder in Docker image @stumpylog (#4347)
- Fix: Retry Tika parsing when Tika returns HTTP 500 @stumpylog (#4334)
- Fix: get highest ASN regardless of user @shamoon (#4326)
- Fix: Generate secret key with C locale and increase allowed characters @stumpylog(#4277)
- Fix: long notes cause visual overflow @shamoon (#4287)
- Fix: Ensures all old connections are closed in certain long lived places @stumpylog(#4265)
- CI: fix playwright browser version mismatch failures @shamoon (#4239)
- Fix: Set a non-zero polling internal when inotify cannot import @stumpylog (#4230)
- Fix: Set permissions before declaring volumes for rootless @stumpylog (#4225)
- Documentation: Fix fuzzy matching details @stumpylog (#4207)
- Fix: application of theme color vars at root @shamoon (#4193)
- Fix: Trim unneeded libraries from Docker image @stumpylog (#4183)
- Fix: support doc_pk storage path placeholder via API @shamoon (#4179)
- Fix: Logs the errors during thumbnail generation @stumpylog (#4171)
- Fix: remove owner details from saved_views api endpoint @shamoon(#4158)
- Fix: dashboard widget card borders hidden by bkgd color @shamoon (#4155)
- Fix: hide entire add user / group buttons if insufficient permissions @shamoon(#4133)
- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224

- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Wer sich das Ganze erstmal vor dem Update live ansehen will, findet hier ein Video und kann es hier auf der Seite von Stefan Lachner selbst ausprobieren.
- Registriert
- 05. März 2013
- Beiträge
- 2.552
- Reaktionspunkte
- 1.113
- Punkte
- 174
Okay, war eine ganz simple Geschichte: In den Rechten fehlte das Recht, die Gruppen anzuzeigen.Das Update hat bei mir auch soweit geklappt, nur wenn ich die Benutzer & Gruppen aufrufe, bekomme ich eine Meldung:

- Registriert
- 03. Jan. 2022
- Beiträge
- 2.271
- Reaktionspunkte
- 1.066
- Punkte
- 224
Paperless-ngx v2.0.1
Repository: paperless-ngx/paperless-ngx · Tag: v2.0.1 · Commit: 65f6b08 · Released by: github-actions[bot]paperless-ngx 2.0.1
Bug Fixes
- Fix: Increase field the length for consumption template source @stumpylog (#4719)
- Fix: Set RGB color conversion strategy for PDF outputs @stumpylog (#4709)
- Fix: Add a warning about a low image DPI which may cause OCR to fail @stumpylog(#4708)
- Fix: share links for URLs containing 'api' incorrect in dropdown @shamoon (#4701)
Hallo auch bei mir läuft die neue Version 2.0.1 super aber ich habe im Stack immer noch stehen:
db:
image: postgres:15.4
container_name: Paperless-NGX-DB
restart: always
sollte ich hier auf die neuste postgres wechseln oder nicht ?
Gibt es hier eine Anleitung wie man das macht ?
db:
image: postgres:15.4
container_name: Paperless-NGX-DB
restart: always
sollte ich hier auf die neuste postgres wechseln oder nicht ?
Gibt es hier eine Anleitung wie man das macht ?


Kaffeautomat
Wenn du das Forum hilfreich findest oder uns unterstützen möchtest, dann gib uns doch einfach einen Kaffee aus.
Als Dankeschön schalten wir deinen Account werbefrei.




